
消息队列介绍
消息队列作用
- 异步处理
- 削峰限流
- 解耦
- 实现分布式事务
- 保证消息顺序处理
- 延时处理
- 数据流处理
异步处理
将用户请求中比较耗时的操作发送到消息队列进行异步处理,减少用户等待。
应用:疫情打卡 Excel 文件导出时,由于文件较大耗时可能较长,可以将导出任务交给消息队列处理。
削峰限流
将短时间内的高并发任务存储在消息队列中,后端服务慢慢根据自己的能力去消费这些消息,避免直接把后端服务打垮。(其实就是漏桶算法)
解耦
基于发布订阅模式,不存在直接调用关系,任务的产生方不需知道由谁来提供服务,任务的服务者也不需要直到是谁发起的任务,可以降低系统的耦合度。
分布式事务
可以将任务从生产到消费的整个过程定义为一个原子操作,要么都成功,要么都失败。
顺序保证
可以使用消息队列保证消息处理的顺序性,防止出现用户先插入后删除,执行时确实先删除后插入的情况出现。
延时处理
消息发送后不会被立即消费,而是达到指定时间之后再消费,比如 10 分钟后取消未支付的订单。
数据流处理
针对分布式系统产生的海量数据流,如业务日志、监控数据、用户行为等,消息队列可以实时或批量收集这些数据,并将其导入到大数据处理引擎中,实现高效的数据流管理和处理。
狭义消息队列
RabbitMQ
RabbitMQ 是使用 Erlang 实现的消息队列,基于 AMQP 协议(是一个应用层协议标准),也提供了其他的协议支持。
RabbitMQ 非常轻量级,他通过 exchange 实现了更灵活的消息路由,其消息存储有集中状态:
- alpha,消息的内容和索引都在内存中;
- beta,消息的内容在磁盘,索引在内存;
- gamma,消息的内容在磁盘,索引在磁盘和内存中都有;
- delta,消息的内容和索引都在磁盘。
在低负载的情况下,数据存储在内存中速度比 kafka 快,但当高负载情况下就不如 kafka 性能好了(kafka 可以实现批量处理而且磁盘 IO 优化的比较好,而 RabbitMQ 在数据量大时会导致内存超出缓冲区,频繁进行换页操作,导致磁盘IO 成为瓶颈)。
RabbitMQ 基于 Erlang 语言的分布式特性实现的集群,但其主要作用还是一个备份容灾,因此扩展性不强,所以如果追求大吞吐量的性能可能不适合选用这个。
RabbitMQ 采用推送模型,把消息推送到队列中再推送到消费者,延迟低,而 kafka、rocketmq 采用拉去模型。
Kafka
消息队列Kafka是什么?架构是怎么样的?5分钟快速入门_哔哩哔哩_bilibili
Kafka 是一个开源流处理平台,最初设计用于收集传输才处理数据流,后来开始增加了不少功能,比如防止消息丢失,解决数据可靠性问题等,现在已经很完善也被用作消息队列,其采用批量处理等思想,性能很强,可以做到极致的吞吐率。
Kafka 是采用 partition 分区的方式来存储 topic(一个 topic 会存储在不同的 partition 中,因此也只有当只有一个partition 的时候才能保证顺序性),并支持基于 Zookeeper 来扩展集群(后来发现 zookeeper 太臃肿也提供了 raft 的解决方案(kraft))。
Kafka 的一个分区底层有多个段(可以理解为文件),如果只有一个文件,相当于顺序写,但如果 topic 的数量增多其实就退化成了随机写,性能就遍低了很多。主从复制的话也需要为每个分区建立同步通道。
Kafka 集群维护比较复杂。
RocketMQ
RocketMQ 是阿里开源的一个高性能、高可靠、高实时的分布式消息队列,设计是参考了 Kafka 并对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。RocketMQ 如果需要保证全局顺序也需要保证只有一个队列存在,会牺牲性能。
RocketMQ 在 Kafka 上进行了架构做减法和功能做加法:
- 架构降级:
- 简化协调节点,不再使用 Zookeeper,使用 NameServer 组件来管理集群信息,更加轻量级
- Rocketmq 的 queue 只存储索引信息,msg 的完整信息存储在一个 commitLog 文件中(多个 topic 都会存到这一个里面);(==这解决了 kafka 多 topic 下的随机写问题==)
- 简化备份模型,直接同步 commitlog 文件就好了。
- 功能加法:
- 消息过滤
- 事务消息(注意 Kafka 所说的事务值发送多条数据到 kafka 保证要么成功要么失败)
- 延时队列
- 死信队列
- 回溯,既可以通过 offset 回溯也可以支持时间回溯(现在 kafka 也支持了)
kafka为什么这么快?RocketMQ哪里不如Kafka?_哔哩哔哩_bilibili
为什么 RocketMQ 吞吐量不如 Kafka 呢?
根本原因在于 RocketMQ 采用的是 mmap 零拷贝,而 kafka 采用的是 sendfile。
RocketMQ 的定时消息、事务消息等也会有额外开销。
Mmap 通过把内核缓冲区数据映射到用户空间,不再需要把数据拷贝到用户缓冲区,只需要三次数据拷贝。(省下一次拷贝)(四次内核态切换,三次数据转换)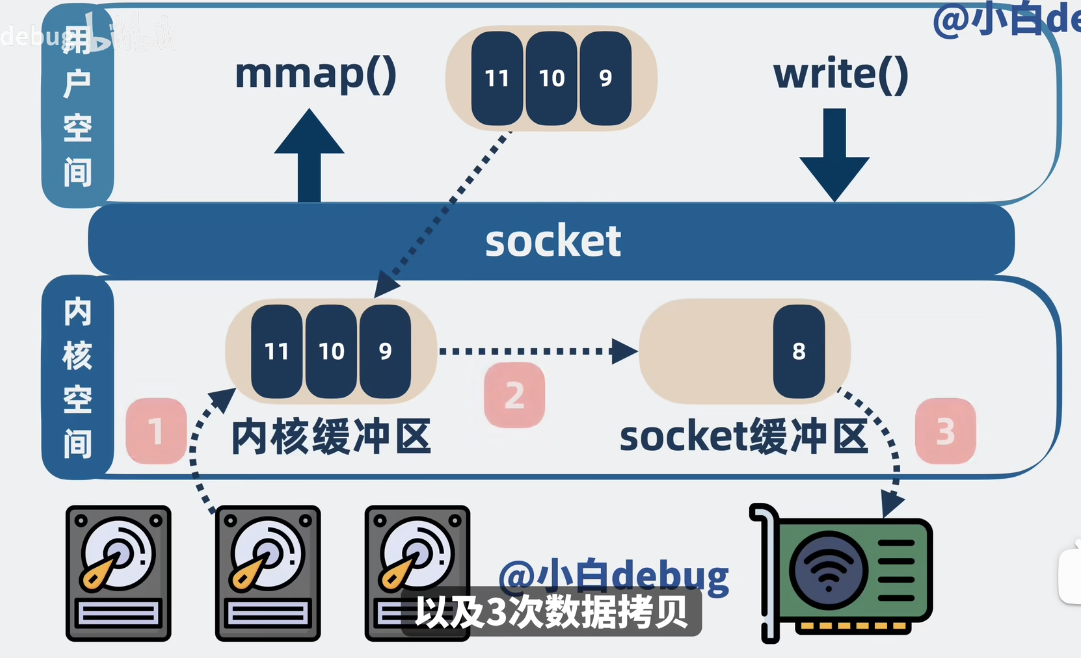
而 sendfile,只需要一次系统调用(两次内核态切换),两次数据拷贝就可以实现了。(基于 DMA 实现拷贝,实现 0CPU 拷贝)
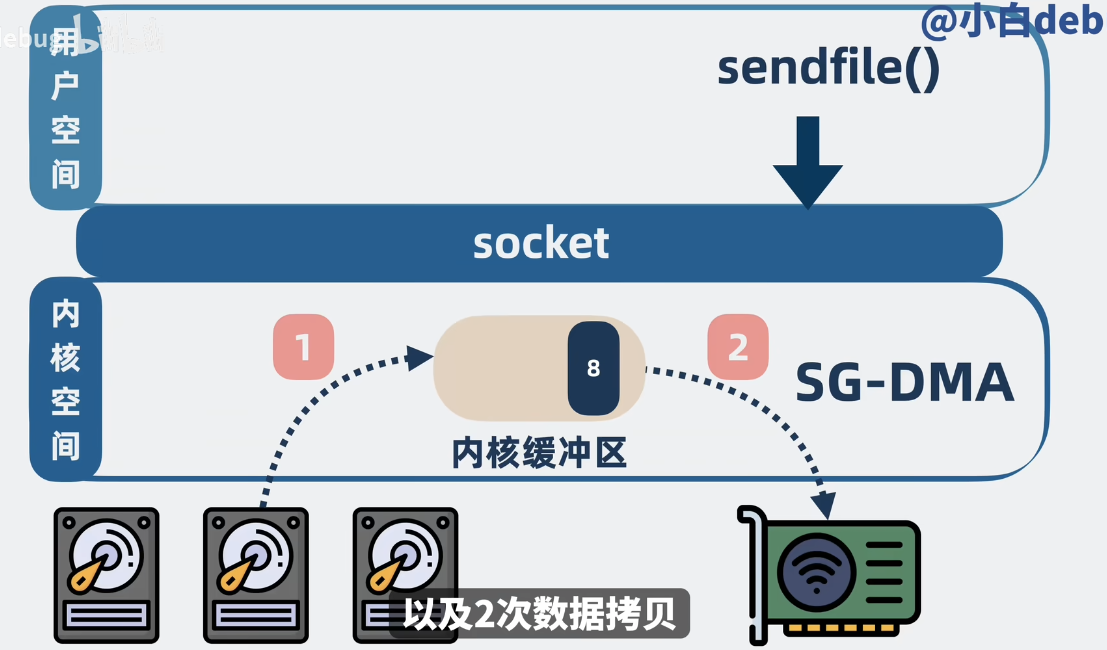
==为什么 RocketMQ 不使用 sendfile 拷贝呢?==
![[Pasted image 20250227215128.png]]
因为 sendfile 返回的是成功发送的字节数,而 mmap 才能返回数据,为了实现私信队列等更多的功能,必须要获取返回的数据才行。相当于 rocketmq 是牺牲了性能,增加了功能。
Pulsar
Apache Pulsar 是 Apache 软件基金会的顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
Pulsar 是存算分离的,存储基于 Bookkeeper,不同的 topic 在内存中排序,最终聚合到大文件中,文件数量少,是顺序 IO,因此性能高。(百万级别 Topic 数量)
对比
这几种消息队列经常被放在一起来比较的,这里也总结以下这几个消息队列的特点:
| 特性 | RabbitMQ | RocketMQ | Kafka | Pulsar |
|---|---|---|---|---|
| 协议支持 | 支持 AMQP、STOMP、MQTT 等 | 自定义协议,支持 JMS 和 MQTT | 仅支持 Kafka 协议 | 自定义协议,支持 MQTT、JMS、AMQP 等 |
| 消息路由 | 灵活复杂 | 简单 | 基于分区 | 支持多租户、分区、强大的消息路由功能 |
| 性能 | 中等 | 较高 | 极高 | 高性能,支持大规模集群扩展 |
| 延迟消息 | 插件支持 | 原生支持 | 无直接支持,需手动实现 | 原生支持延迟队列和定时消息 |
| 持久化与存储 | 支持持久化,但性能较弱 | 支持高可靠性存储 | 强大的日志存储机制 | 支持多层次存储,消息持久化,PB级存储 |
| 消息顺序 | 支持严格顺序(单一队列) | 支持顺序消息(通过分区) | 支持顺序消息(通过分区) | 支持严格顺序消息和无序消息 |
| 水平扩展性 | 扩展性有限 | 支持水平扩展 | 高度可扩展,支持大规模数据流 | 非常高,支持独立存储与计算层扩展,PB级存储 |
| 多租户支持 | 不支持 | 不支持 | 不支持 | 支持多租户、命名空间和资源配额管理 |
| 流式处理 | 不适用 | 不适用 | 与 Kafka Streams 集成支持流式处理 | 原生支持流式处理和集成 Pulsar Functions |
| 使用场景 | 适合小型到中型的消息传递,复杂路由需求 | 适合分布式事务、金融、电商等 | 适合日志收集、大数据流处理 | 适合多租户、PB级消息量、高吞吐量的应用 |
总结以下:
- Rabbitmq 轻量级,低负载下速度快,高负载下磁盘 I/O 成为瓶颈,性能低,且集群比较简单,主要是做备份。
- Kafka 采用分区机制处理 topic(这也导致了 topic 比较多的时候,退化成随机 IO 性能低),基于 sendfile 追求极致性能,但其架构负载臃肿,配置复杂。
- RocketMQ 是一个折中方案,对 kafka 的架构做了减法对功能做了加法。只能采用 mmap,性能不如 kafka,但解决了 kafka 的大量 topic 性能下降问题。
广义消息队列
MQTT
MQTT(Message Queuing Telemetry Transport) 是一种轻量级、基于发布-订阅模式的消息传输协议,适用于资源受限的设备和低带宽、高延迟或不稳定的网络环境。它在物联网应用中广受欢迎,能够实现传感器、执行器和其它设备之间的高效通信。而且也可以应用在网络直播互动、手机消息推送等行业场景。详细可参考 [[MQTT协议]]
其实 MQTT 并不是算是一个消息队列,只是两者的特性比较相近,但他们的出发点和应用场景是有着显著不同的:
- 消息队列作为一种中间件,主要用于服务端应用之间的消息存储与转发,数据量大但客户端数量少。
- MQTT 是一种消息传输协议,主要用于物联网设备间的消息传递,特点是连接的设备量很大。
而且相比消息队列,MQTT 的主题不需要提前创建,在订阅或发布时即自动的创建了主题,开发者无需再关心主题的创建,并且也不需要手动删除主题。
优点
- 延迟很低
- 可自定义可靠性 QoS
- 支持大量设备连接
- 适合资源受限的设备使用
- 报文长度小,通信开销低
缺点
- 吞吐量不如狭义上的消息队列中间件
总结
MQTT 也是基于 broker 架构的,但是定位是一个通信协议,但和狭义上的消息队列中间件算是殊途同归,但该通信协议比较轻量级,报文长度小,支持海量设备连接,适用于物联网场景。有时 MQTT 和消息队列会一起使用,MQTT 专注于处理物联网设备上报的数据,然后消息队列订阅这些消息并转发到不同的业务系统进行处理。而且 RabbitMQ 也内置了 MQTT 插件,来实现 MQTT 功能。
ZeroMQ
严格来说 ZeroMQ 是一个基于消息队列模型的网络库,它并不一定需要其他消息队列的 broker 中间件,非中心化架构,提供了 PUSH-PULL、PUB-SUB、Router-Dealer 等模式。使用起来很像 Socket。
优点
- 去中心化,减少单点故障
- 配置简单
- 灵活性高
- 点对点,低延迟高吞吐量
- 跨平台
缺点
- 复杂功能依赖程序员自己实现
- 不保证消息持久化
- 有些模式下消息顺序无法保证
总结
非中心化的基于消息队列模型的网络库,灵活,性能高,但使用负责,需要额外手段保证消息持久化,适用于简单的高性能传输场景,也可以根据自己的需求灵活实现相关功能。
基于 Redis 的消息队列
Redis 作为一款内存 KV 存储系统也可以作为轻量级的消息队列使用,可以基于两种方案实现:
- 发布订阅模式
- List
- Stream
发布订阅模式无法提供持久化,消息发送后就会销毁,消费端如果掉线后消息就丢失了,而且无法处理消息积压。
List 数据接口可以当作队列来使用,将其作为消息队列的原理如下:
- 消息保序:使用 LPUSH + RPOP;
- 阻塞读取:使用 BRPOP;
- 重复消息处理:生产者自行实现全局唯一 ID;
- 消息的可靠性:使用 BRPOPLPUSH
但缺点是不支持多个消费者消费同一条消息,一旦消费者拿到一条消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费。而且由于是内存型数据库,如果消息堆积过多会导致无法写入数据(如果采用了淘汰策略会导致数据丢失)
而 Redis 5.0 提供了 Stream 这个数据结构就是专门为消息队列设计的,其提供了消费组的概念可以实现多个消费者消费,具体可以参考 Redis 常见数据类型和应用场景 | 小林coding
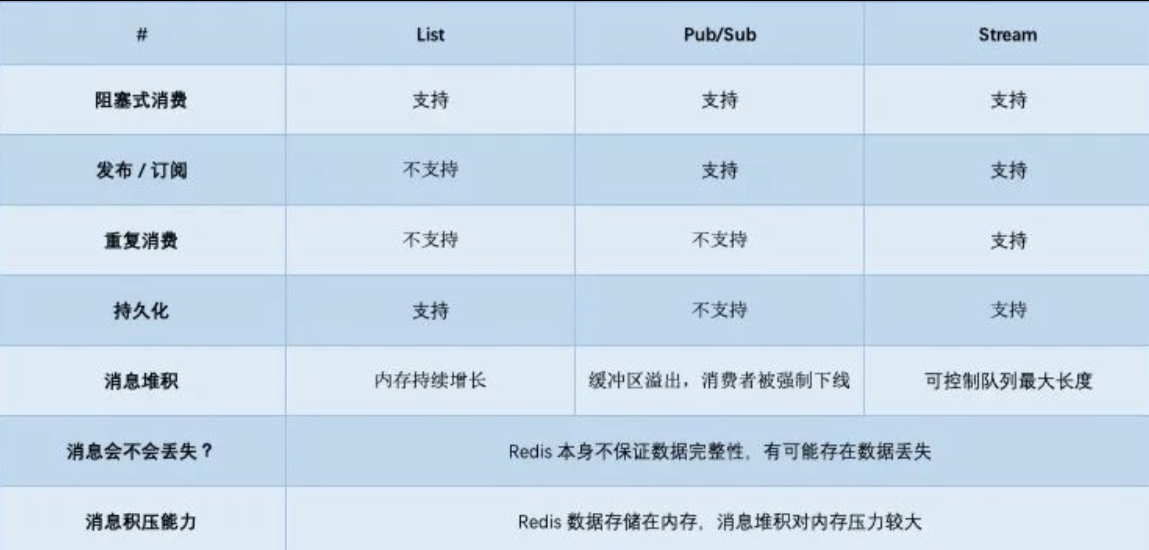
图片源于 把Redis当作队列来用,真的合适吗?-腾讯云开发者社区-腾讯云
优点
- 简单、轻量级
- 易部署
- 延迟低
对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。测试数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。实验表明:入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。
缺点
- 不能保证消息完全不丢失
- 内存存储,空间资源紧张,难以应对大量消息积压场景
- 功能较为简陋
总结
Redis 可以作为一个轻量级的消息队列使用,适用于简单业务,对数据丢失不敏感,且消息积压概率比较低的场景
Disruptor
本质是一个开源的系统内部的高性能内存队列,而不是分布式队列,用于线程间的数据传递,主要解决了 JDK 内置线程安全队列的性能和内存安全问题。提供了一个无锁有界的队列,相比内置队列性能更高。具体可以参考高性能队列——Disruptor - 美团技术团队
参考资料
消息队列基础知识总结 | JavaGuide
Redis 常见数据类型和应用场景 | 小林coding
把Redis当作队列来用,真的合适吗?-腾讯云开发者社区-腾讯云
# Kafka、RabbitMQ、RocketMQ 之间的区别是什么 ?
高性能队列——Disruptor - 美团技术团队
Weixin Official Accounts Platform