犀牛鸟开源人才培养计划Apache-InLong项目整理总结
在今年七月学院老师发了腾讯犀牛鸟开源人才培养计划 的通知,我也一直有参与一些较大开源项目的意愿,所以就马上报了名,该项目有很多子项目供选择,当时仔细考虑发现对Apache InLong项目最为感兴趣,也和自己的方向比较契合,所以就报名参加了InLong项目的开源课题实践。主要以Issue的形式参与开源项目,在参与的过程中,对InLong项目的理解更加深入,而且熟悉了开源项目的贡献流程。编码能力提高的同时,代码规范性也获得了提升。
InLong介绍 官方对InLong的介绍如下:
InLong(应龙),中国神话故事里的神兽,引流入海,借喻 InLong 系统提供数据集成能力。
Apache InLong(应龙)是一站式、全场景的海量数据集成框架,同时支持数据接入、数据同步和数据订阅,提供自动、安全、可靠和高性能的数据传输能力,方便业务构建基于流式的数据分析、建模和应用。 InLong 项目原名 TubeMQ ,专注于高性能、低成本的消息队列服务。为了进一步释放 TubeMQ 周边的生态能力,我们将项目升级为 InLong,专注打造一站式、全场景海量数据集成框架。 Apache InLong 依托 10 万亿级别的数据接入和处理能力,整合了数据采集、汇聚、存储、分拣数据处理全流程,拥有简单易用、灵活扩展、稳定可靠等特性。 该项目最初于 2019 年 11 月由腾讯大数据团队捐献到 Apache 孵化器,2022 年 6 月正式毕业成为 Apache 顶级项目。目前 InLong 正广泛应用于广告、支付、社交、游戏、人工智能等各个行业领域,为多领域客户提供高效化便捷化服务。
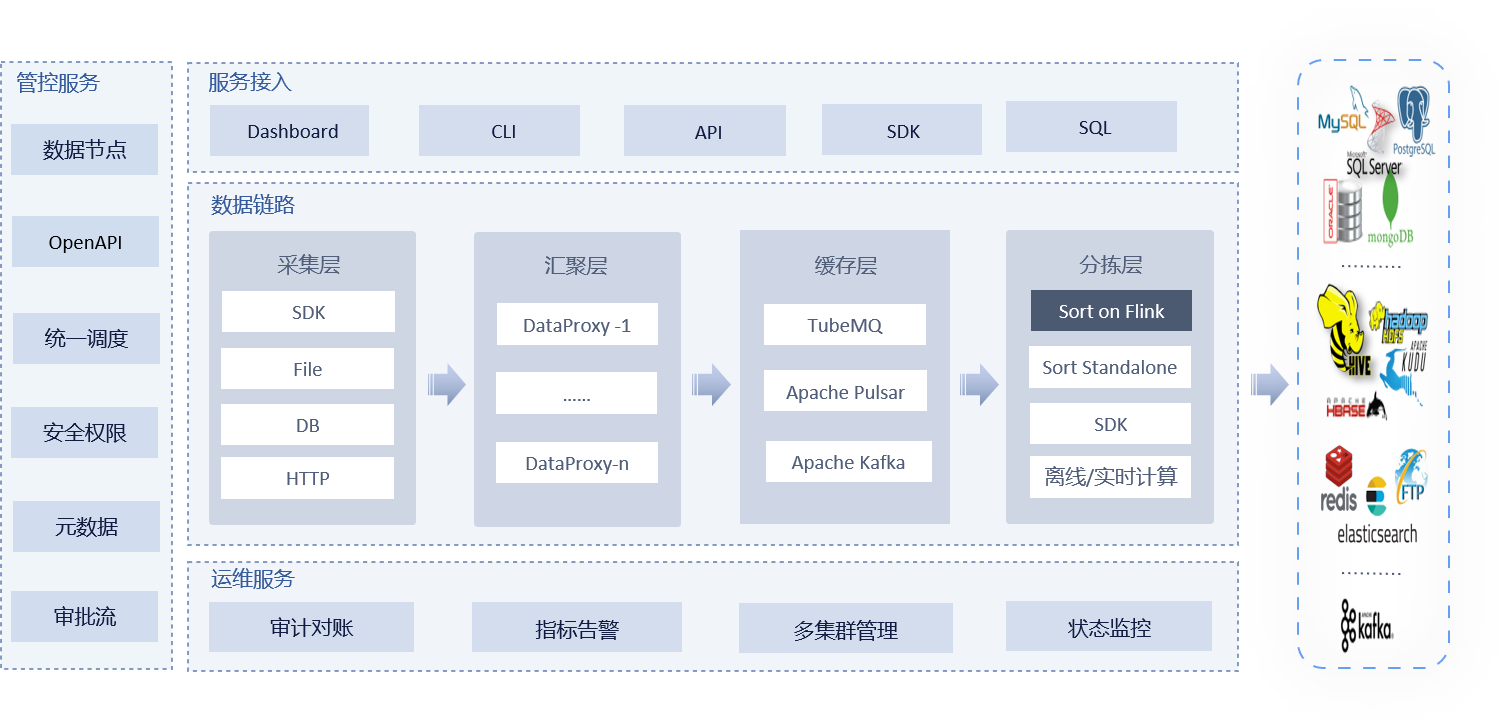
该项目的架构如下:
主要是由几大模块构成:
Agent:用来采集数据DataProxy:数据转发MQ:消息队列Sort:基于Flink的ETL处理Manager:整个服务的管控,提供了OpenAPIDashboard:管理系统前端页面,调用manager后端接口Audit:审计模块
在项目参与过程中主要参与了Agent、Sort和DataProxy SDK模块的开发。
MQTT Source开发
该Issue是我参与的第一个InLong Issue,是为Agent模块编写支持从MQTT数据源读取数据的Source,之所以选择这个Issue主要是之前做数字孪生项目时有用过MQTT。虽然需求很简单,但是我花费了很长的时间在阅读项目源码,梳理运行逻辑以及部署测试环境上。
主要参考InLong文档中的Agent插件开发说明进行开发。
主要的逻辑在MqttSource类中,主要逻辑还是比较简单的,在initSource函数中初始化mqtt连接的相关参数,并初始化connect,当有新的订阅消息到来时,会被放到LinkedBlockingQueue阻塞队列中去,之后可以调用readFromSource方法从阻塞队列中读取数据。之所以采用阻塞队列,因为这个场景是一种典型的生产者-消费者模型,可以使用队列作为中间缓冲,可以平衡生产者(mqtt消息)和消费者(readFromSource)的处理能力,当生产者效率高于消费者时,还能起到削峰填谷的作用。
public class MqttSource extends AbstractSource { private static final Logger LOGGER = LoggerFactory.getLogger(MqttSource.class); private MqttClient client; private LinkedBlockingQueue<DefaultMessage> mqttMessagesQueue; private String serverURI; private String topic; private int qos; private String clientId; MqttConnectOptions options; public MqttSource () { } @Override protected String getThreadName () { return "mqtt-source-" + taskId + "-" + instanceId; } @Override protected void initSource (InstanceProfile profile) { try { LOGGER.info("MqttSource init: {}" , profile.toJsonStr()); mqttMessagesQueue = new LinkedBlockingQueue <>(profile.getInt(TaskConstants.TASK_MQTT_QUEUE_SIZE, 1000 )); serverURI = profile.get(TaskConstants.TASK_MQTT_SERVER_URI); instanceId = profile.getInstanceId(); topic = profile.get(TaskConstants.TASK_MQTT_TOPIC); qos = profile.getInt(TaskConstants.TASK_MQTT_QOS, 1 ); clientId = profile.get(TaskConstants.TASK_MQTT_CLIENT_ID_PREFIX, "mqtt_client" ) + "_" + UUID.randomUUID(); initConnectOptions(profile); mqttConnect(); } catch (Exception e) { stopRunning(); throw new FileException ("error init stream for {}" + topic, e); } } private void initConnectOptions (InstanceProfile profile) { options = new MqttConnectOptions (); options.setCleanSession(profile.getBoolean(TaskConstants.TASK_MQTT_CLEAN_SESSION, false )); options.setConnectionTimeout(profile.getInt(TaskConstants.TASK_MQTT_CONNECTION_TIMEOUT, 10 )); options.setKeepAliveInterval(profile.getInt(TaskConstants.TASK_MQTT_KEEPALIVE_INTERVAL, 20 )); options.setUserName(profile.get(TaskConstants.TASK_MQTT_USERNAME, "" )); options.setPassword(profile.get(TaskConstants.TASK_MQTT_PASSWORD, "" ).toCharArray()); options.setAutomaticReconnect(profile.getBoolean(TaskConstants.TASK_MQTT_AUTOMATIC_RECONNECT, true )); options.setMqttVersion( profile.getInt(TaskConstants.TASK_MQTT_VERSION, MqttConnectOptions.MQTT_VERSION_DEFAULT)); } private void mqttConnect () { try { client = new MqttClient (serverURI, clientId, new MemoryPersistence ()); client.setCallback(new MqttCallback () { @Override public void connectionLost (Throwable cause) { LOGGER.error("the mqtt jobId:{}, serverURI:{}, connection lost, {} " , instanceId, serverURI, cause); reconnect(); } @Override public void messageArrived (String topic, MqttMessage message) throws Exception { Map<String, String> headerMap = new HashMap <>(); headerMap.put("record.topic" , topic); headerMap.put("record.messageId" , String.valueOf(message.getId())); headerMap.put("record.qos" , String.valueOf(message.getQos())); byte [] recordValue = message.getPayload(); mqttMessagesQueue.offer(new DefaultMessage (recordValue, headerMap), 1 , TimeUnit.SECONDS); } @Override public void deliveryComplete (IMqttDeliveryToken token) { } }); client.connect(options); client.subscribe(topic, qos); LOGGER.info("the mqtt subscribe topic is [{}], qos is [{}]" , topic, qos); } catch (Exception e) { LOGGER.error("init mqtt client error {}. jobId:{},serverURI:{},clientId:{}" , e, instanceId, serverURI, clientId); } } private void reconnect () { if (!client.isConnected()) { try { client.connect(options); LOGGER.info("the mqtt client reconnect success. jobId:{}, serverURI:{}, clientId:{}" , instanceId, serverURI, clientId); } catch (Exception e) { LOGGER.error("reconnect mqtt client error {}. jobId:{}, serverURI:{}, clientId:{}" , e, instanceId, serverURI, clientId); } } } private void disconnect () { try { client.disconnect(); } catch (MqttException e) { LOGGER.error("disconnect mqtt client error {}. jobId:{},serverURI:{},clientId:{}" , e, instanceId, serverURI, clientId); } } @Override protected void printCurrentState () { LOGGER.info("mqtt topic is {}" , topic); } @Override protected boolean doPrepareToRead () { return true ; } @Override protected List<SourceData> readFromSource () { List<SourceData> dataList = new ArrayList <>(); try { int size = 0 ; while (size < BATCH_READ_LINE_TOTAL_LEN) { Message msg = mqttMessagesQueue.poll(1 , TimeUnit.SECONDS); if (msg != null ) { SourceData sourceData = new SourceData (msg.getBody(), "0L" ); size += sourceData.getData().length; dataList.add(sourceData); } else { break ; } } } catch (InterruptedException e) { LOGGER.error("poll {} data from mqtt queue interrupted." , instanceId); } return dataList; } @Override protected boolean isRunnable () { return runnable; } @Override protected void releaseSource () { LOGGER.info("release mqtt source" ); if (client.isConnected()) { disconnect(); } } @Override public boolean sourceExist () { return true ; } }
为了提高读数据的效率,每次可以获取一批数据,而不是一条数据,所以这里做了一些优化:借助阻塞队列的poll(long timeout, TimeUnit unit)方法,尝试循环获取多条数据,如果超时说明队列中可能没有数据了,则返回。
在整理的时候发现如果消息入队设置了超时机制会导致队列满时消息丢失问题,所以mqttMessagesQueue.offer(new DefaultMessage(recordValue, headerMap), 1, TimeUnit.SECONDS);应该修改为mqttMessagesQueue.offer(new DefaultMessage(recordValue, headerMap)); 具体参见 [INLONG-11175][Agent] Fix the problem of mqttsource message loss #11176 .
OpenTelemetry集成 这部分内容是项目的第三阶段开源实践的任务,也是我花费时间精力比较多的地方,有三个课题供选择,需要报名和选拔后组队完成,我选择了Integrate Sort with OpenTelemetry 课题,该课题需求为采用OpenTelemetry来实现Sort日志的集中上报。
[Umbrella] Tencent Rhino-bird: Integrate Sort with OpenTelemetry #10798
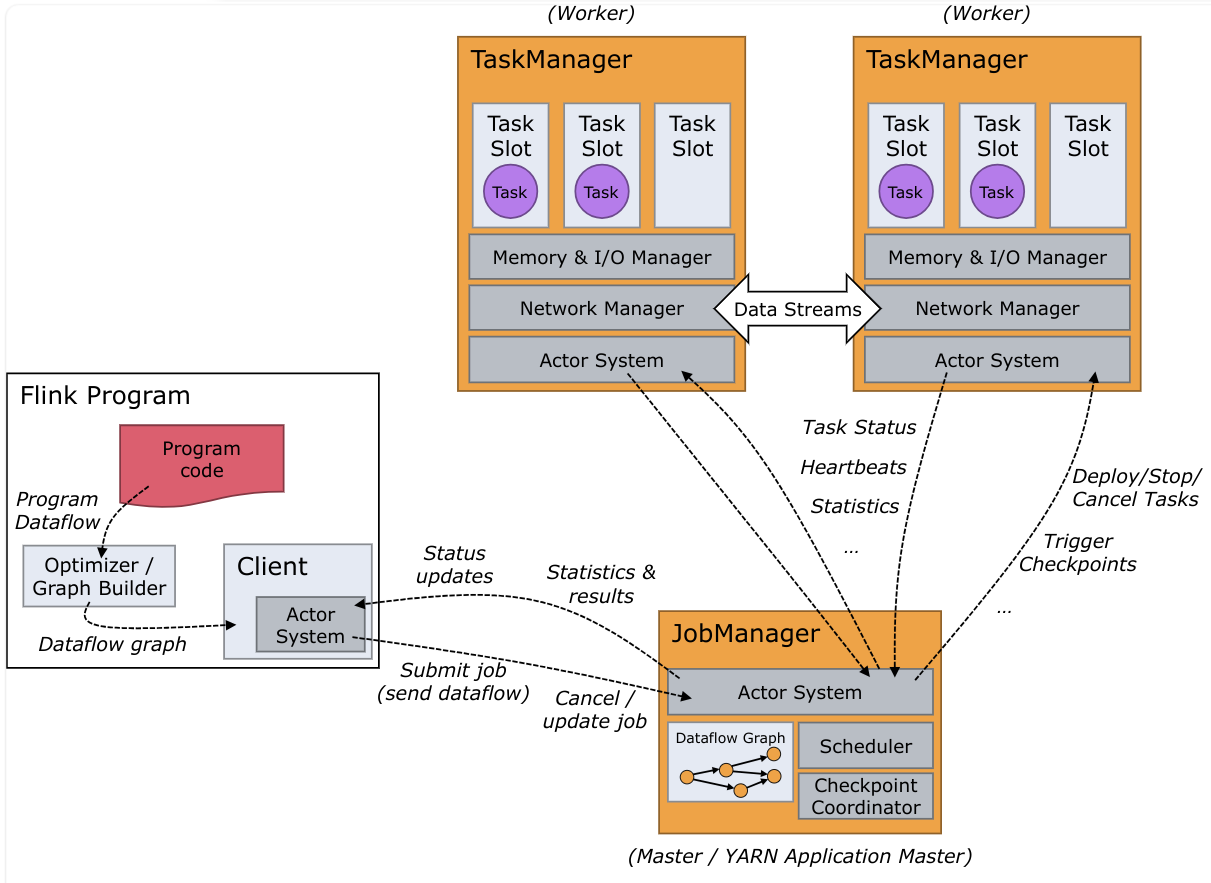
任务背景 在InLong中Sort模块是一个基于 Apache Flink 的ETL系统,其提供了一些connector的InLong实现,提供了审计、脏数据处理、多表同步、内存优化等特性。首先来看一下flink的运行流程:
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager,一个 Flink 应用程序从提交到完成的流程大致上可以表述为:
InLong-Manager根据任务信息构造JobGraph,并将它们发送给 JobManagerJobManager 接收到 JobGraph 后,会将其转换为 ExecutionGraph,然后向集群申请资源并将 ExecutionGraph 分发给对应的 TaskManagerTaskManager 接收到 ExecutionGraph 后,会将作业流进行拆分并交由 Task Slot 处理Task Slot 完成计算后,由 Sink 任务实现结果的输出
而Connector的作用就相当于一个连接器,连接 Flink计算引擎跟外界存储系统,TaskManager会使用这些Connector来进行数据读写。
可以看到ETL任务是分散到不同TaskManager的Slot上进行计算的,尽管我们可以在Flink JobManager的UI界面上看到异常类型,但如果TaskManager上出现了一些非致命异常,任务不会中止,排查问题就只能进入每一个TaskManager去查看异常日志,问题排查流程比较繁琐。所以我们希望能够将这些异常日志统一收集起来进行处理,提高系统的可观测性。以上就是这个Issue需要解决的问题。
解决方案 为了实现日志的集中管理,可采用OpenTelemetryAppender将日志上报到OpenTelemetryCollector,然后进一步将日志传送给Grafana Loki、Signoz等可视化平台进行集中展示。
日志采集 OpenTelemetry其实提供了三个维度的功能:Trace,Metrics和Log,这里我们主要关注日志方面的功能,使用OpenTelemetry最简单的方式是借助OpenTelemetry Java Agent进行自动埋点,无须手动配置,但我们不能采用这种方式,一方面这种方式的自定义化能力差,另一方面在Flink中也不方便去使用Java Agent特性。因此采用了第二种方案:OpenTelemetry Java SDK手动上报日志:
由于InLong项目主要采用了Log4j2作为日志框架,所以我们需要修改Log4j2的配置文件来增加OpenTelemetryAppender,官方 给出了xml格式的配置文件:
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status ="WARN" > <Appenders > <Console name ="Console" target ="SYSTEM_OUT" > <PatternLayout pattern ="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} trace_id: %X{trace_id} span_id: %X{span_id} trace_flags: %X{trace_flags} - %msg%n" /> </Console > <OpenTelemetry name ="OpenTelemetryAppender" /> </Appenders > <Loggers > <Root > <AppenderRef ref ="OpenTelemetryAppender" level ="All" /> <AppenderRef ref ="Console" level ="All" /> </Root > </Loggers > </Configuration >
然后按照SDK的官方示例配置OpenTelemetry SDK,这样Appender就会将日志上报到指定的EndPoint地址。
public class Main { private static final org.apache.logging.log4j.Logger log4jLogger = LogManager.getLogger("log4j-logger" ); public static void main (String[] args) { OpenTelemetry openTelemetry = initializeOpenTelemetry(); io.opentelemetry.instrumentation.log4j.appender.v2_17.OpenTelemetryAppender.install(openTelemetry); log4jLogger.info("A log4j log message without a span" ); log4jLogger.info("A log4j log message with a span" ); Map<String, Object> mapMessage = new HashMap <>(); mapMessage.put("key" , "value" ); mapMessage.put("message" , "A log4j structured message" ); log4jLogger.info(new MapMessage <>(mapMessage)); ThreadContext.clearAll(); log4jLogger.error("A log4j log message with an exception" , new Exception ("error!" )); } private static OpenTelemetry initializeOpenTelemetry () { OpenTelemetrySdk sdk = OpenTelemetrySdk.builder() .setTracerProvider(SdkTracerProvider.builder().setSampler(Sampler.alwaysOn()).build()) .setLoggerProvider( SdkLoggerProvider.builder() .setResource( Resource.getDefault().toBuilder() .put(ResourceAttributes.SERVICE_NAME, "test" ) .build()) .addLogRecordProcessor( BatchLogRecordProcessor.builder( OtlpGrpcLogRecordExporter.builder() .setEndpoint("http://127.0.0.1:4317" ) .build()) .build()) .build()) .build(); Runtime.getRuntime().addShutdownHook(new Thread (sdk::close)); return sdk; } }
接下来需要启动一个opentelemetry-collector服务,这里采用的是docker compose的形式启动的容器,docker-compose.yml文件增加如下内容(其实这里也有一个坑,OpenTelemetry官方给的示例是跑不通的,因为新版本的镜像采用localhost作为endpoint的话,外部无法访问,这里给Opentelemetry-java-examples提了一个pr修复了这个问题,详见Fix log-append collector can not output logs problem. #475 ):
collector: image: otel/opentelemetry-collector-contrib:0.107.0 volumes: - ./otel-config.yaml:/otel-config.yaml command: ["--config=/otel-config.yaml" ] ports: - "4317:4317"
同时增加一个otel-config.yaml的配置映射文件:
receivers: otlp: protocols: grpc: endpoint: collector:4317 exporters: logging: verbosity: detailed service: pipelines: logs: receivers: [otlp ] exporters: [logging ]
启动容器后,运行注册了Opentelemetry SDK的java项目,即可在collector的容器日志中查看到上报的日志信息。接下来我们需要为InLong-Sort的connector赋予日志上报的能力,sort模块提供了flink-1.13、flink 1.15和flink 1.18的connector实现,目前主要使用的是1.15版本,Flink原始的Source接口(SourceFunction)随着Flink在数据集成和流批一体上的不断发展, 暴露出了越来越多的问题. 为了实现更优雅的数据接入, 社区提出了FLIP-27 来重构Source接口。在新的标准中每个connector需要编写一个SourceReader类来处理与数据存储对象的交互,所以我们可以在SourceReader的start方法中install sdk,并在close方法中uninstall sdk,以mysql-connector为例,我们可以进行如下修改来为其注册OpenTelemetry SDK:
public class MySqlSourceReader <T> extends SingleThreadMultiplexSourceReaderBase <SourceRecords, T, MySqlSplit, MySqlSplitState> { private static final Logger LOG = LoggerFactory.getLogger(MySqlSourceReader.class); private final MySqlSourceConfig sourceConfig; private final Map<String, MySqlSnapshotSplit> finishedUnackedSplits; private final Map<String, MySqlBinlogSplit> uncompletedBinlogSplits; private final int subtaskId; private final MySqlSourceReaderContext mySqlSourceReaderContext; private MySqlBinlogSplit suspendedBinlogSplit; private final DebeziumDeserializationSchema<T> metricSchema; private OpenTelemetrySdk SDK; public MySqlSourceReader ( FutureCompletingBlockingQueue<RecordsWithSplitIds<SourceRecords>> elementQueue, Supplier<MySqlSplitReader> splitReaderSupplier, RecordEmitter<SourceRecords, T, MySqlSplitState> recordEmitter, Configuration config, MySqlSourceReaderContext context, MySqlSourceConfig sourceConfig, DebeziumDeserializationSchema<T> metricSchema) { super ( elementQueue, new SingleThreadFetcherManager <>(elementQueue, splitReaderSupplier::get), recordEmitter, config, context.getSourceReaderContext()); this .sourceConfig = sourceConfig; this .finishedUnackedSplits = new HashMap <>(); this .uncompletedBinlogSplits = new HashMap <>(); this .subtaskId = context.getSourceReaderContext().getIndexOfSubtask(); this .mySqlSourceReaderContext = context; this .suspendedBinlogSplit = null ; this .metricSchema = metricSchema; } @Override public void start () { this .SDK = OpenTelemetrySdk.builder() .setLoggerProvider( SdkLoggerProvider.builder() .setResource( Resource.getDefault().toBuilder() .put(ResourceAttributes.SERVICE_NAME, "log4j-example" ) .build()) .addLogRecordProcessor( BatchLogRecordProcessor.builder( OtlpGrpcLogRecordExporter.builder() .setEndpoint("http://127.0.0.1:4317" ) .build()) .build()) .build()) .build(); OpenTelemetryAppender.install(SDK); if (getNumberOfCurrentlyAssignedSplits() == 0 ) { context.sendSplitRequest(); } } @Override public void close () throws Exception { super .close(); SDK.close(); } ... ...
为了验证日志上报功能,将该mysql-connector打为jar包,然后在本地的flink上提交一个mysql的ETL任务,由于Flink的Log4j2配置文件为properties格式,前面提到的xml配置格式并不适用,需要增加如下配置内容:
packages = io.opentelemetry.instrumentation.log4j.appender.v2_17 rootLogger.appenderRef.OpenTelemetryAppender.ref = OpenTelemetryAppender appender.OpenTelemetryAppender.type = OpenTelemetry appender.OpenTelemetryAppender.name = OpenTelemetryAppender appender.OpenTelemetryAppender.captureMapMessageAttributes = true
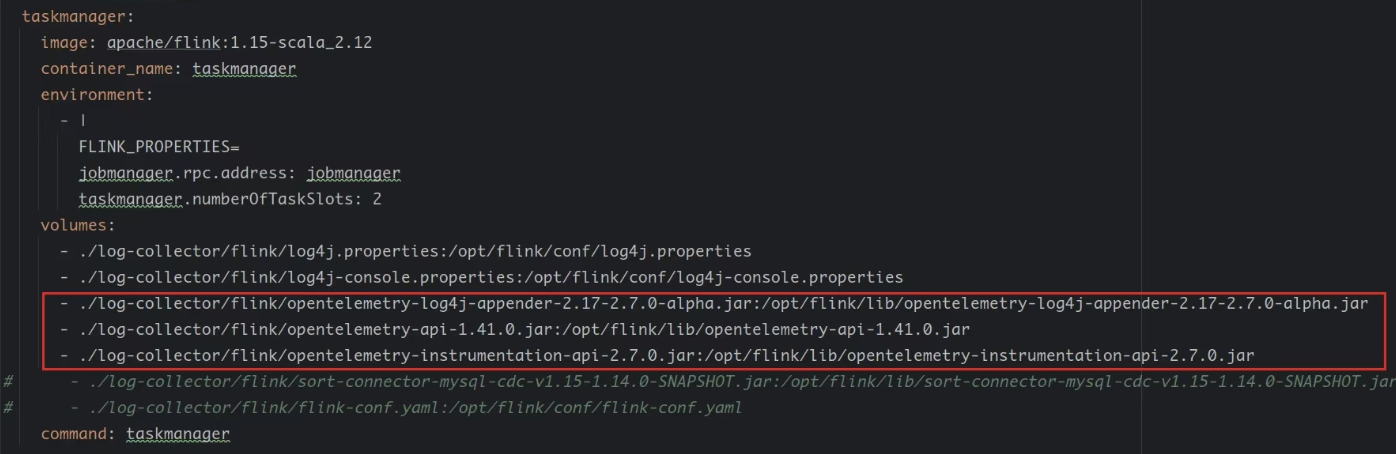
启动Flink集群,提交任务,可以在collector中查看到TaskManager上报的日志,至此日志上报流程已经打通,但在InLong的数据同步流程中测试发现是存在问题的,因为按照InLong的流程,Connector是Manager提交给Flink的,也就是说Flink在启动的时候是没有包含集成了Opentelemetry的Connector的,那么就会导致Flink启动的时候在类加载路径lib中找不到OpenTelemetry的log4j2 Appender,导致日志模块出错。当时我想既然没有,那我手动给他加一个不就行了吗,为此我给flink的lib目录中映射了一个OpentelemetryAppender的jar包:
但测试发现,虽然Flink启动不报错了,但是日志仍然没有发送到collector,这就让我非常疑惑,那我们就得从日志上报的过程入手查找原因了,会不会是Install SDK的时候有问题呢?为此我去查看了OpenTelemetry SDK的源码,其中install函数如下:
public static void install (OpenTelemetry openTelemetry) { org.apache.logging.log4j.spi.LoggerContext loggerContextSpi = LogManager.getContext(false ); if (!(loggerContextSpi instanceof LoggerContext)) { return ; } LoggerContext loggerContext = (LoggerContext) loggerContextSpi; Configuration config = loggerContext.getConfiguration(); config .getAppenders() .values() .forEach( appender -> { if (appender instanceof OpenTelemetryAppender) { ((OpenTelemetryAppender) appender).setOpenTelemetry(openTelemetry); } }); }
可以看到其便利了当前的log4j2的所有appender,针对OpenTelemetryAppender类型的Appender进行处理,会不会是没有识别到OpenTelemetryAppender呢,我在代码逻辑中进行了输出,发现是有OpenTelemetryAppender类型的appender存在的,也就是说Flink在初始化时OpenTelemetryAppender是加载成功的,但我惊奇的发现if (appender instanceof OpenTelemetryAppender)这个判断居然没能进入!!,仔细思考发现其实是我们拿到的log4j2中的OpenTelemetryAppender是lib路径下的类,而在SDK中判断的是connector中的OpenTelemetryAppender类,而JVM判断类是否相同的规则如下:
JVM 不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。即使两个类来源于同一个 Class 文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相同。
那么分析到这里问题就很清楚了:**Flink加载的OpenTelemetryAppender和Connector中使用的OpenTelemetryAppender并不是同一个类**。那么能不能让Connector也采用Flink的lib路径中的OpenTelemetryAppender类呢?我尝试在打包Connector的过程中删除掉OpenTelemetryAppender相关的jar包,试图让connector去Flink的lib路径下查找这个包,结果证明是行不通的类呢?答案是不可以,因为java的类型转换只能在存在集成关系的对象之间进行转换,很遗憾这两个类是不同路径下的两个类,没有继承关系。
走到这一步似乎没办法推进了,但前面花费了很大的时间和精力不甘心就此放弃,就再次回到了install的源码中想解决方案,这时我突然灵机一动,既然我们可以通过Configuration config = loggerContext.getConfiguration();获取到log4j2的所有Appender,那是否可以在Connector中手动地增加OpenTelemetry Appender而不是在log4j2的日志中增加呢?这样我们就不需要在Flink初始化的时候加载Appender,可以保证Log4j2中的OpenTelemetryAppender就是connector中的OpenTelemetryAppender了。借助Log4j2文档,可以发现是支持addAppender 操作的(其实后面应该再好好读以下源码),那只要在connector的start方法中增加OpenTelemetryAppender然后在close中remove掉就可以了,这样也免去对了Flink配置文件的修改,既支持在InLong流程中使用,也支持作为一个Connector在Flink中独立使用。
为了减少对Connector的修改,封装了一个如下的OpenTelemetryLogger工具类,同时采用Builder模式来构建Appender进行配置。
package org.apache.inlong.sort.base.util;import io.opentelemetry.exporter.otlp.logs.OtlpGrpcLogRecordExporter;import io.opentelemetry.instrumentation.log4j.appender.v2_17.OpenTelemetryAppender;import io.opentelemetry.sdk.OpenTelemetrySdk;import io.opentelemetry.sdk.OpenTelemetrySdkBuilder;import io.opentelemetry.sdk.logs.SdkLoggerProvider;import io.opentelemetry.sdk.logs.SdkLoggerProviderBuilder;import io.opentelemetry.sdk.logs.export.BatchLogRecordProcessor;import io.opentelemetry.sdk.resources.Resource;import io.opentelemetry.semconv.resource.attributes.ResourceAttributes;import org.apache.logging.log4j.Level;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.core.Layout;import org.apache.logging.log4j.core.LoggerContext;import org.apache.logging.log4j.core.config.Configuration;import org.apache.logging.log4j.core.config.LoggerConfig;import org.apache.logging.log4j.core.layout.PatternLayout;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.nio.charset.StandardCharsets;public class OpenTelemetryLogger { private OpenTelemetrySdk SDK; private final String endpoint; private final String serviceName; private final Layout<?> layout; private final Level logLevel; private final String localHostIp; private static final Logger LOG = LoggerFactory.getLogger(OpenTelemetryLogger.class); public OpenTelemetryLogger (Builder builder) { this .serviceName = builder.serviceName; this .endpoint = builder.endpoint; this .layout = builder.layout; this .logLevel = builder.logLevel; this .localHostIp = builder.localHostIp; } public OpenTelemetryLogger (String serviceName, String endpoint, Layout<?> layout, Level logLevel, String localHostIp) { this .serviceName = serviceName; this .endpoint = endpoint; this .layout = layout; this .logLevel = logLevel; this .localHostIp = localHostIp; } public static final class Builder { private String endpoint; private String serviceName; private Layout<?> layout; private Level logLevel; private String localHostIp; public Builder () { } public Builder setServiceName (String serviceName) { this .serviceName = serviceName; return this ; } public Builder setLayout (Layout<?> layout) { this .layout = layout; return this ; } public Builder setEndpoint (String endpoint) { this .endpoint = endpoint; return this ; } public Builder setLogLevel (Level logLevel) { this .logLevel = logLevel; return this ; } public Builder setLocalHostIp (String localHostIp) { this .localHostIp = localHostIp; return this ; } public OpenTelemetryLogger build () { if (this .serviceName == null ) { this .serviceName = "unnamed_service" ; } if (this .endpoint == null ) { if (System.getenv("OTEL_EXPORTER_ENDPOINT" ) != null ) { this .endpoint = System.getenv("OTEL_EXPORTER_ENDPOINT" ); } else { this .endpoint = "localhost:4317" ; } } if (this .layout == null ) { this .layout = PatternLayout.newBuilder() .withPattern("%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" ) .withCharset(StandardCharsets.UTF_8) .build(); } if (this .logLevel == null ) { this .logLevel = Level.INFO; } return new OpenTelemetryLogger (this ); } } private void createOpenTelemetrySdk () { OpenTelemetrySdkBuilder sdkBuilder = OpenTelemetrySdk.builder(); SdkLoggerProviderBuilder loggerProviderBuilder = SdkLoggerProvider.builder(); Resource resource = Resource.getDefault().toBuilder() .put(ResourceAttributes.SERVICE_NAMESPACE, "inlong_sort" ) .put(ResourceAttributes.SERVICE_NAME, this .serviceName) .put(ResourceAttributes.HOST_NAME, this .localHostIp) .build(); loggerProviderBuilder.setResource(resource); OtlpGrpcLogRecordExporter exporter = OtlpGrpcLogRecordExporter.builder() .setEndpoint("http://" + this .endpoint) .build(); BatchLogRecordProcessor batchLogRecordProcessor = BatchLogRecordProcessor.builder(exporter).build(); loggerProviderBuilder.addLogRecordProcessor(batchLogRecordProcessor); sdkBuilder.setLoggerProvider(loggerProviderBuilder.build()); SDK = sdkBuilder.build(); } private void addOpenTelemetryAppender () { org.apache.logging.log4j.spi.LoggerContext context = LogManager.getContext(false ); LoggerContext loggerContext = (LoggerContext) context; Configuration config = loggerContext.getConfiguration(); OpenTelemetryAppender otelAppender = OpenTelemetryAppender.builder() .setName("OpenTelemetryAppender" ) .setLayout(this .layout) .build(); otelAppender.start(); config.addAppender(otelAppender); LoggerConfig loggerConfig = config.getLoggerConfig(LogManager.ROOT_LOGGER_NAME); loggerConfig.addAppender(otelAppender, this .logLevel, null ); loggerContext.updateLoggers(); } private void removeOpenTelemetryAppender () { org.apache.logging.log4j.spi.LoggerContext context = LogManager.getContext(false ); LoggerContext loggerContext = (LoggerContext) context; Configuration config = loggerContext.getConfiguration(); config.getAppenders().values().forEach(appender -> { if (appender instanceof OpenTelemetryAppender) { config.getRootLogger().removeAppender(appender.getName()); appender.stop(); } }); loggerContext.updateLoggers(); } public void install () { addOpenTelemetryAppender(); createOpenTelemetrySdk(); OpenTelemetryAppender.install(SDK); LOG.info("OpenTelemetryLogger installed" ); } public void uninstall () { LOG.info("OpenTelemetryLogger uninstalled" ); SDK.close(); removeOpenTelemetryAppender(); } }
对于符合FLIP-27的connector只需要进行如下修改即可完成日志上报:
在构造函数中初始化openTelemetryLogger
在start中openTelemetryLogger.install();
在close中openTelemetryLogger.uninstall();
import org.apache.inlong.sort.base.util.OpenTelemetryLogger;public class XXXSourceReader <T>{ private static final Logger LOG = LoggerFactory.getLogger(MySqlSourceReader.class); private final OpenTelemetryLogger openTelemetryLogger; public XXXSourceReader () { ... this .openTelemetryLogger = new OpenTelemetryLogger .Builder() .setServiceName(this .getClass().getSimpleName()) .setLocalHostIp(this .context.getLocalHostName()).build(); } @Override public void start () { openTelemetryLogger.install(); ... } @Override public void close () throws Exception { openTelemetryLogger.uninstall(); super .close(); } ... }
日志可视化 通过上面的工作,我们已经实现了将日志集中上报到OpenTelemetry Collector,但在collector中并不是很方便进行查看,效率比较低,所以我们还需要进一步地集成日志可视化平台,我调研了两个方案:
Grafana Loki Signoz ELK(Elasticsearch、logstash、Kibana)
ELK是一个比较重量级的日志解决方案,所以主要是在前两个方案中做选择,由于还有另一位同学参与这个实践项目,所以我们选择分头行动,我负责Loki的实现,他负责Signoz的实现。
Grafana Loki是Grafana的一个子插件,是一个开源的一个水平可扩展、高可用性,多租户的日志聚合系统的日志聚合系统。它的设计初衷是为了解决在大规模分布式系统中,处理海量日志的问题。其主要特性是不对日志进行全文索引,通过存储压缩非结构化日志和仅索引元数据,更加轻量,操作更加简单,更加节省成本。这样的话日志的数据流如下:
为了将日志进一步上传到Loki需要对前面OpenTelemetry collector的配置otel-config.yaml进行修改:
receivers: otlp: protocols: grpc: endpoint: logcollector:4317 processors: batch: exporters: logging: verbosity: detailed otlphttp: endpoint: http://loki:3100/otlp tls: insecure: true service: pipelines: logs: receivers: [otlp ] processors: [batch ] exporters: [otlphttp , logging ]
在docker-compose.yml文件中增加loki,grafana容器,同时为flink增加指向collector地址的环境变量,其中grafana的entrypoint部分是为了自动配置loki插件,免去了手动安装的步骤:
jobmanager: image: apache/flink:1.15-scala_2.12 container_name: jobmanager environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager - OTEL_EXPORTER_ENDPOINT=logcollector:4317 ports: - "8081:8081" command: jobmanager taskmanager: image: apache/flink:1.15-scala_2.12 container_name: taskmanager environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager taskmanager.numberOfTaskSlots: 2 - OTEL_EXPORTER_ENDPOINT=logcollector:4317 command: taskmanager logcollector: image: otel/opentelemetry-collector-contrib:0.110.0 container_name: logcollector volumes: - ./log-system/otel-config.yaml:/otel-config.yaml command: [ "--config=/otel-config.yaml" ] ports: - "4317:4317" loki: image: grafana/loki:3.0.0 ports: - "3100:3100" volumes: - ./log-system/loki.yaml:/etc/loki/local-config.yaml command: -config.file=/etc/loki/local-config.yaml grafana: environment: - GF_PATHS_PROVISIONING=/etc/grafana/provisioning - GF_AUTH_ANONYMOUS_ENABLED=true - GF_AUTH_ANONYMOUS_ORG_ROLE=Admin entrypoint: - sh - -euc - | mkdir -p /etc/grafana/provisioning/datasources cat <<EOF > /etc/grafana/provisioning/datasources/ds.yaml apiVersion: 1 datasources: - name: Loki type: loki access: proxy orgId: 1 url: http://loki:3100 basicAuth: false isDefault: true version: 1 editable: false EOF /run.sh image: grafana/grafana:latest ports: - "3000:3000"
Loki的配置文件如下:
auth_enabled: false limits_config: allow_structured_metadata: true volume_enabled: true otlp_config: resource_attributes: attributes_config: - action: index_label attributes: - level server: http_listen_port: 3100 common: ring: instance_addr: 0.0 .0 .0 kvstore: store: inmemory replication_factor: 1 path_prefix: /tmp/loki schema_config: configs: - from: 2020-05-15 store: tsdb object_store: filesystem schema: v13 index: prefix: index_ period: 24h storage_config: tsdb_shipper: active_index_directory: /tmp/loki/index cache_location: /tmp/loki/index_cache filesystem: directory: /tmp/loki/chunks pattern_ingester: enabled: true
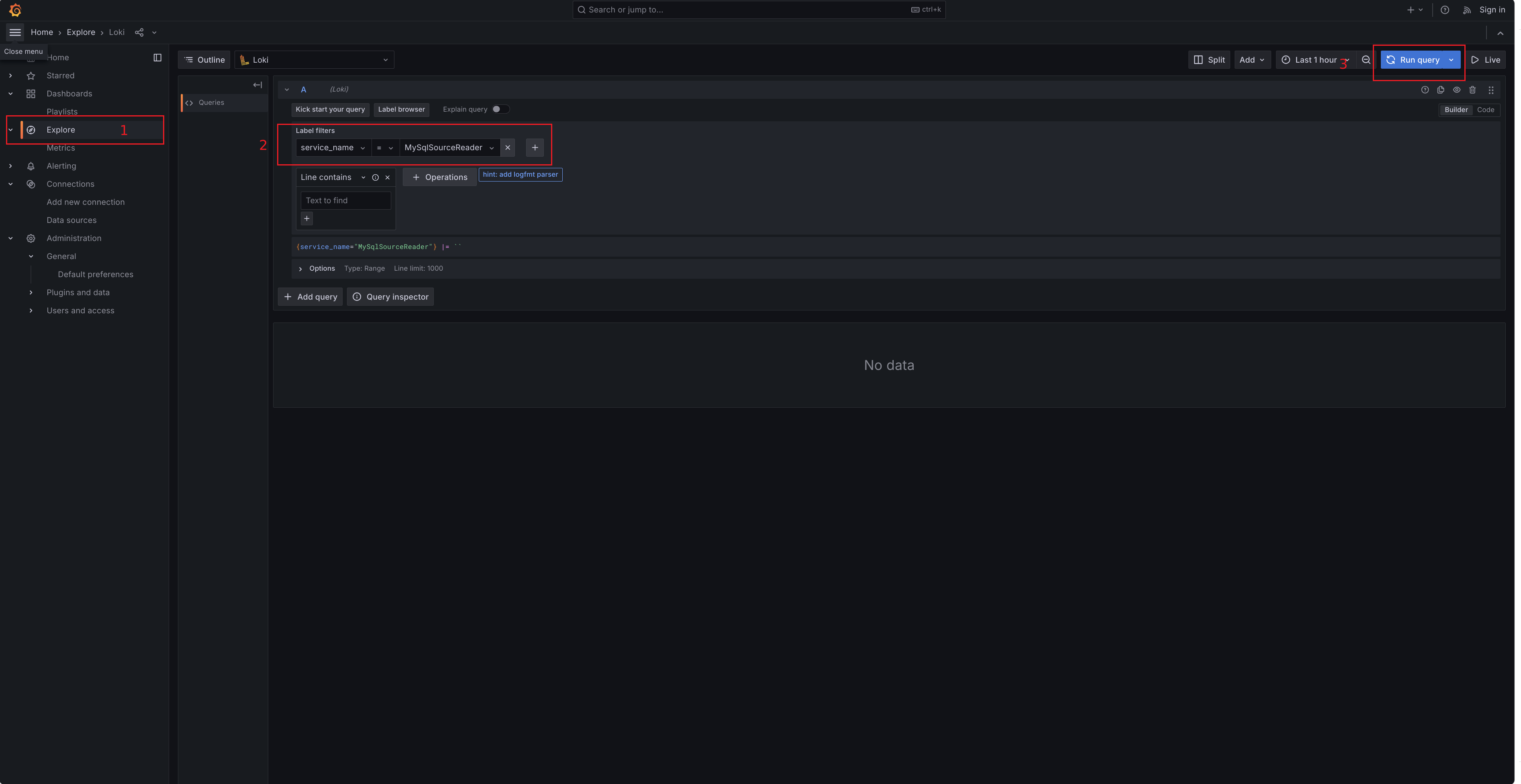
启动docker-compose,可以通过http://127.0.0.1:3000/explore地址进入Grafana Loki界面,通过service_name字段进行日志查询:
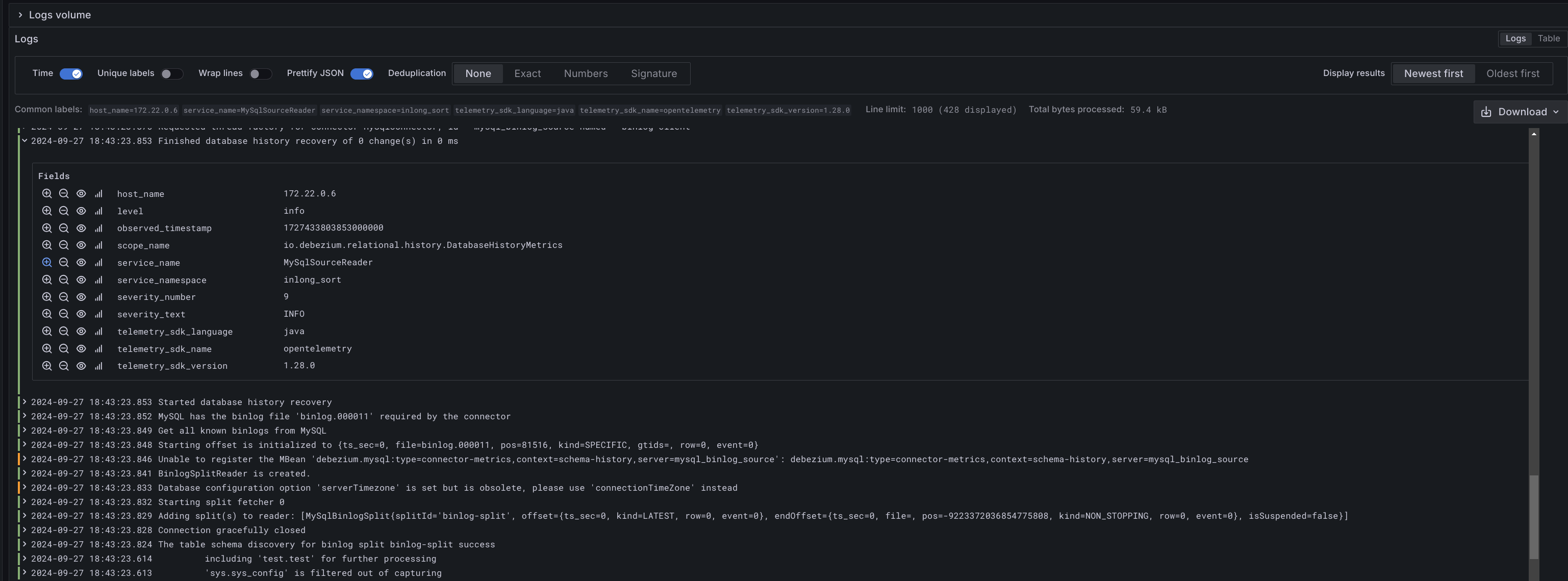
并通过点击相应的日志项,查看日志的详细信息:
注意:因为loki3之后适配了otel协议,之前opentelemetry提供的exporter已经弃用,现在直接用otel协议上报给grafna loki就行了;然而最新的loki 3.10.0 有bug,没办法完成opentelemetry 日志标准到loki标准的日志级别转换,上面使用的3.0.0 版本是ok的,可以等一下官方修复这个问题。
DataProxy SDK 超长字段处理优化
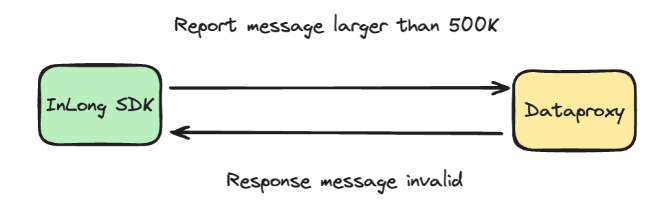
DataProxy一次最多只能处理500k bytes的消息长度,而SDK并没有限制上报数据的大小,会导致传输时数据截断,DataProxy无法接收到完整的数据结构,导致无法反序列化恢复数据造成message invalid错误。
因此该Issue需要为SDK提供超长数据自动截断功能,把用户发送的超长数据截断,保证数据结构的完整性,具体需求如下:
在 SDK 中支持自动超长数据截断
用户可配置的自动截断
提供允许的数据长度的默认值
在写这个issue的时候,发现官方给的example是有问题的,主要是对isLocalVisit变量的描述和使用,这里还对example的代码和文档进行了以下修正:
为了实现上述需求,主要做了以下工作:
在 inlong-sdk/data-sdk/src/main/java/org/apache/inlong/sdk/data/ConfigConstants.java 中添加了 MAX _ MESSAGE _ LENGTH 常量,来配置允许的数据长度。
提供了一个 DataTruncationUtil 来实现数据截断。
为DefaultMessageSender.java 添加了 enableDataTruncation 属性,以设置是否启用自动截断函数。并添加了一个用户可以调用的配置函数。
将数据截断逻辑添加到所有 sendMessage 和 syncSendMessage 接口。
主要内容为DataTruncationUtil工具类
public class DataTruncationUtil { public static byte [] truncateData(byte [] body) { if (body.length > ConfigConstants.MAX_MESSAGE_LENGTH) { byte [] newBody = new byte [ConfigConstants.MAX_MESSAGE_LENGTH]; System.arraycopy(body, 0 , newBody, 0 , ConfigConstants.MAX_MESSAGE_LENGTH); return newBody; } else { return body; } } public static List<byte []> truncateData(List<byte []> bodyList) { int size = 0 ; List<byte []> newBodyList = new ArrayList <>(); for (byte [] body : bodyList) { if (body.length + size <= ConfigConstants.MAX_MESSAGE_LENGTH) { newBodyList.add(body); size += body.length; } else { byte [] newBody = new byte [ConfigConstants.MAX_MESSAGE_LENGTH - size]; System.arraycopy(body, 0 , newBody, 0 , ConfigConstants.MAX_MESSAGE_LENGTH - size); newBodyList.add(newBody); break ; } } return newBodyList; } }
针对单个的数据body,只需要在超出长度时进行截断即可,而对于一组bodyList<byte[]> bodyList需要进行累加处理。
但上述方案在进行CR的时候,有社区老师提出截断操作无法保证用户报告的数据完整性,而且如果数据是被编码或者压缩过的,那么不完整的bytes会造成无法恢复的问题。
为此我增加一个用户可选的配置项来允许用户自行配置是否启用截断功能:
if (enableDataTruncation) { body = truncateData(body); }
但经过和社区老师的沟通,在Inlong的场景下确实是无论如何也不能发送不完整的数据的,因此修改成了只要超出配置的最大长度就直接拒绝的方案:
对于同步发送接口直接return SendResult.BODY_EXCEED_MAX_LEN即可
对于异步发送接口需要调用SendMessageCallable的onMessageAck接口返回超出长度限制信息callback.onMessageAck(SendResult.BODY_EXCEED_MAX_LEN);
社区老师提出了一个新的改进方案,配置改为从Manager模块下发,通过仔细阅读了相关代码捋清了整个逻辑,DataProxy SDK在发送数据前会向Manager的/dataproxy/getIpList/{inlongGroupId}接口请求dataproxy集群信息,并借助该集群信息去构建一个Sender,那么如果能给此接口的返回信息中添加上最大长度配置字段就可以实现从Manager下发配置的需求。